Erster Eindruck zählt:
Sieht erst mal voll kompliziert aus!
Wer soll da durchsehen?
Wozu brauch ich den ganzen Kram überhaupt?
Keine Panik.
Hier gibt es Tipps und Tricks zum Umgang mit dem Screaming Frog.
Inhaltsverzeichnis
Video-Aufzeichnung
Wir haben die Erklärung zum Screaming Frog während des Nesthäkchen-Meetings aufgezeichnet. Das Video dazu mit Steffis Gelaber findet ihr im OneDrive.
Was ist der Screaming Frog?
Der Screaming Frog ist ein Tool zum vollautomatischen Crawlen von Websites. Das funktioniert ähnlich wie bei Google. Ein Bot (kleines Programm) geht auf die Website, die wir eingeben, und schaut sich alle Seiten und Dokumente an, die es auf dieser Website gibt. Dazu zählen HTML-Seiten, Javascript- und CSS-Dateien, Bilder, PDFs etc. Das Tool gibt dann eine Liste mit diesen Seiten und Dokumenten aus. Aber nicht nur das. Wir erhalten viele verschiedene Informationen und Details über diese Seiten und Dokumente – und sogar über ihre Beziehungen untereinander.
Welche Informationen bietet der Screaming Frog?
Der Screaming Frog liefert uns Details über alle URLs einer Website.
- URL (inkl. Bewertung, ob Zeichen drin sind, die da nicht rein gehören)
- Typ der URL (z.B. HTML, Bild, PDF, Javascript etc.)
- Statuscode beim Abrufen (z.B. 200 = alles ok oder 301 = Weiterleitung)
- Indexierbarkeit (index / noindex und ggf. warum no-index)
- Meta-Daten und deren Länge (inkl. zu lang / zu kurz / fehlt)
- H1- & H2-Überschriften und deren Länge (inkl. zu lang / zu kurz / fehlt)
- Meta Robots Tags (z.B. „index,follow“)
- Canonical Link
- Größe in Kilobyte (v.a. interessant für Bilder und andere Dateien)
- Wörteranzahl
- Crawl-Tiefe
- Inlinks: Anzahl der internen Seiten, die auf diese URL verlinken (gesamt & einzigartige) → im unteren Fenster: Übersicht über verlinkende Seiten bei „Inlinks“
- Outlinks: Anzahl der internen Seiten, die von dieser URL aus verlinkt sind (gesamt & einzigartige) → im unteren Fenster: Übersicht über verlinkte Seiten bei „Outlinks“
- Outlinks extern: Anzahl der externen Seiten, die von dieser URL aus verlinkt sind(gesamt & einzigartige) → im unteren Fenster: Übersicht über verlinkte Seiten auch bei „Outlinks“
- Datum der letzten Änderung
- Bei Weiterleitungen: Die weitergeleitete URL und die URL, an die weitergeleitet wird
Mithilfe des Screaming Frog kann man beispielsweise kaputte interne Links finden.
Aber Achtung bei den externen Links: Wir sehen bei den externen Links nur Infos zu anderen Websites, die von unserer Seite aus verlinkt sind, nicht Backlinks zu uns!
Was sollte man einstellen, bevor man auf „Start“ drückt?
Ihr könnt bestimmte Einstellungen vornehmen, bevor ihr überhaupt den Crawl startet. Das solltet ihr vor allem bei umfangreichen Websites unbedingt tun. Sonst rödelt der Screaming Frog ewig und frisst gegebenenfalls zu viel Rechenleistung, wenn er drölftausend URLs mit Parametern, umfangreiche Bildergalerien oder hunderte Javascript-Dateien crawlen muss. Außerdem könnt ihr den Crawler explizit einstellen, falls ihr testen wollt, wie bspw. der Google Bot für Mobil die Seite sieht.
Spider-Einstellungen anpassen
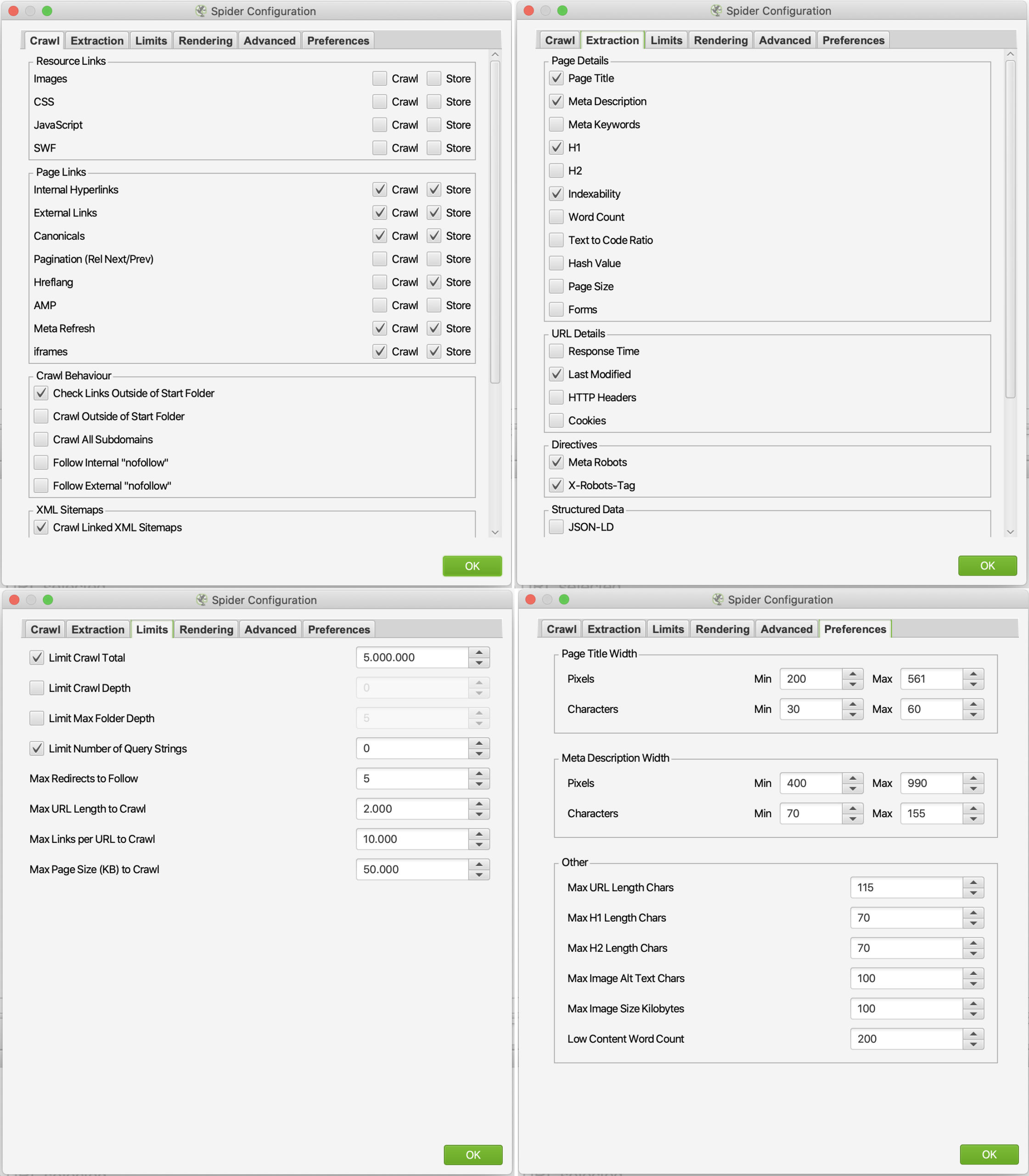
Bevor es losgeht, solltet ihr bestimmte Daten ein- bzw. ausschließen. So könnt ihr ganz gezielt crawlen oder zumindest verhindern, dass der Frog unnötige Daten mit in die Liste spült. Dazu sind bei Configuration > Spider die ersten drei und der letzte Reiter besonders interessant.
Beispiel-Einstellungen:
User Agent (Bot) einstellen
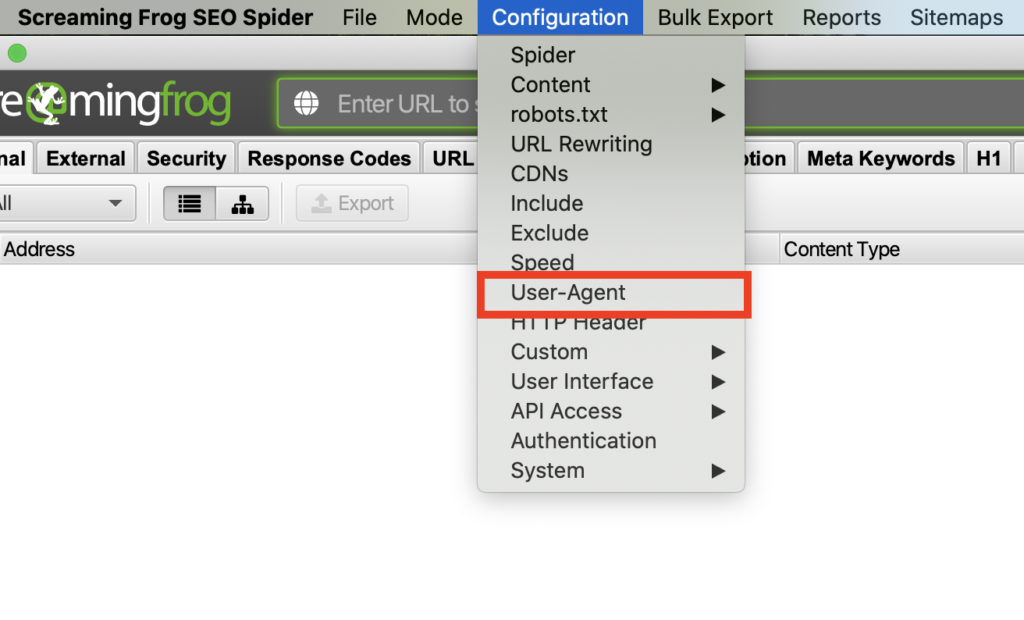
Manchmal werden Bots außer Google blockiert, dann würde auch der Screaming Frog Bot die URLs nicht richtig auslesen können. Stellt am besten immer den Google Bot (Desktop oder Mobil) ein. Dazu auf Configuration > User-Agent gehen und den gewünschten Bot auswählen.
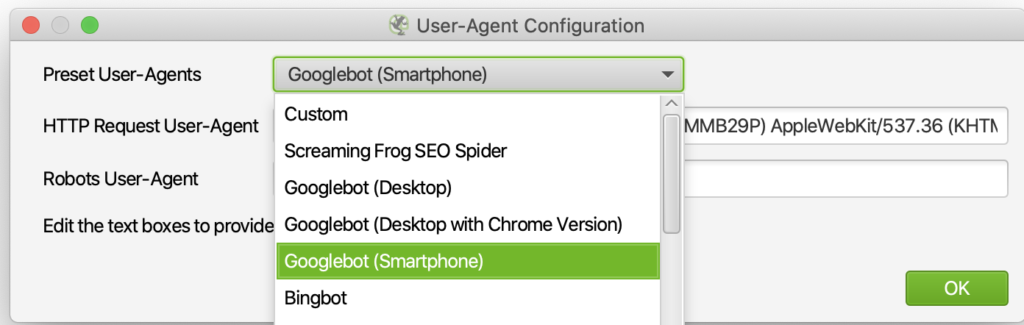
Standard-Konfiguration speichern
Wenn ihr eine Konfiguration eingestellt habt, die ihr oft benutzt, dann habt ihr die Möglichkeit, diese als Standard zu speichern. Bereitet dazu alles vor, das ihr braucht bzw. ausschließen wollt, stellt den Crawler ein etc. Und dann speichert ihr die aktuelle Konfiguration als Standard. Wenn ihr das nächste Mal den Screaming Frog öffnet, ist schon alles eingestellt und ihr könnt loslegen.
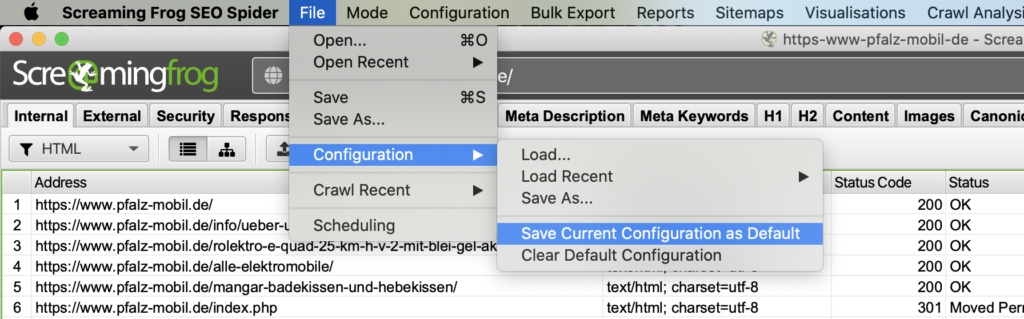
Bonus: Kein Plan, was ein Häkchen oder eine Einstellung macht?
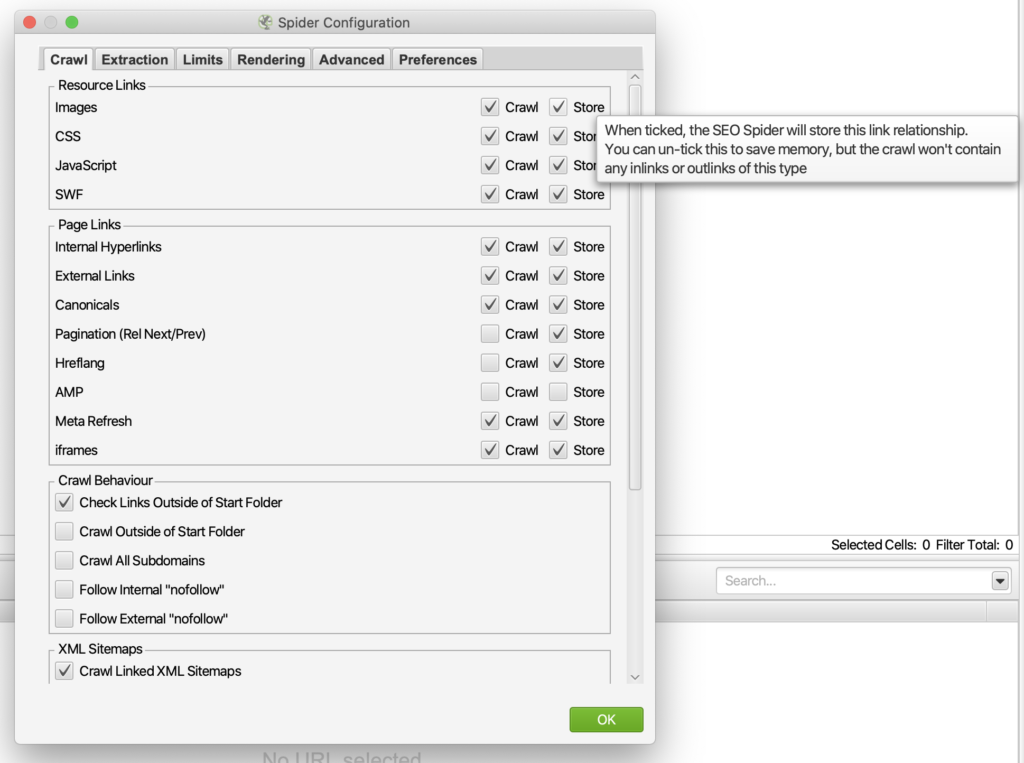
Screaming Frog’s got your back. Einfach mal mit dem Mauszeiger über das Häkchen hovern und schon öffnet sich ein Tooltip mit Infos über die Einstellung und ihre Auswirkungen. Ansonsten gibt’s auch einen umfangreichen User Guide auf der Screaming Frog Website.
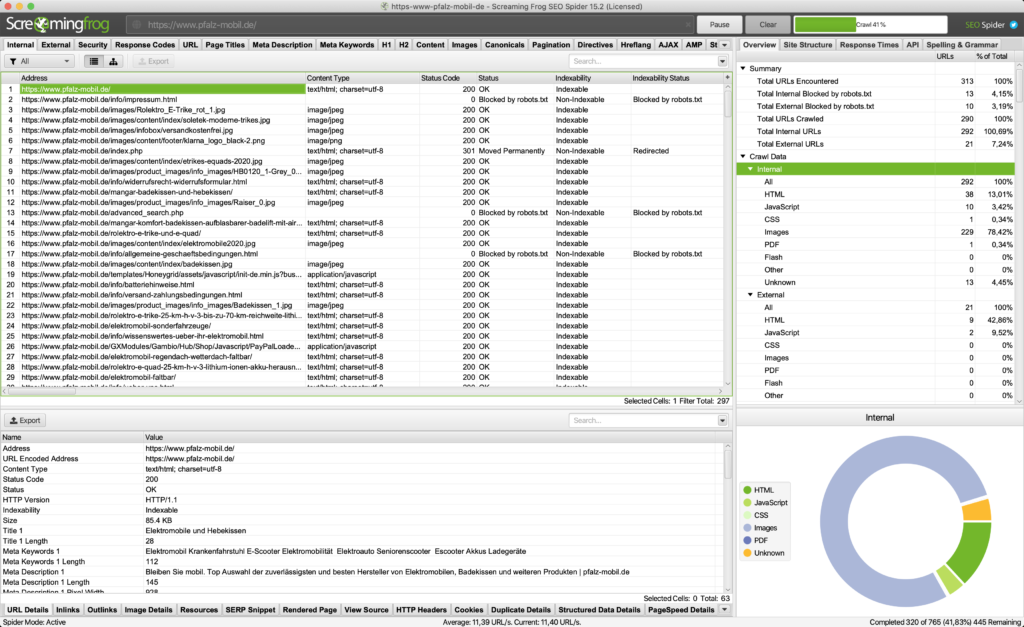
Was zeigen die einzelnen Fenster?
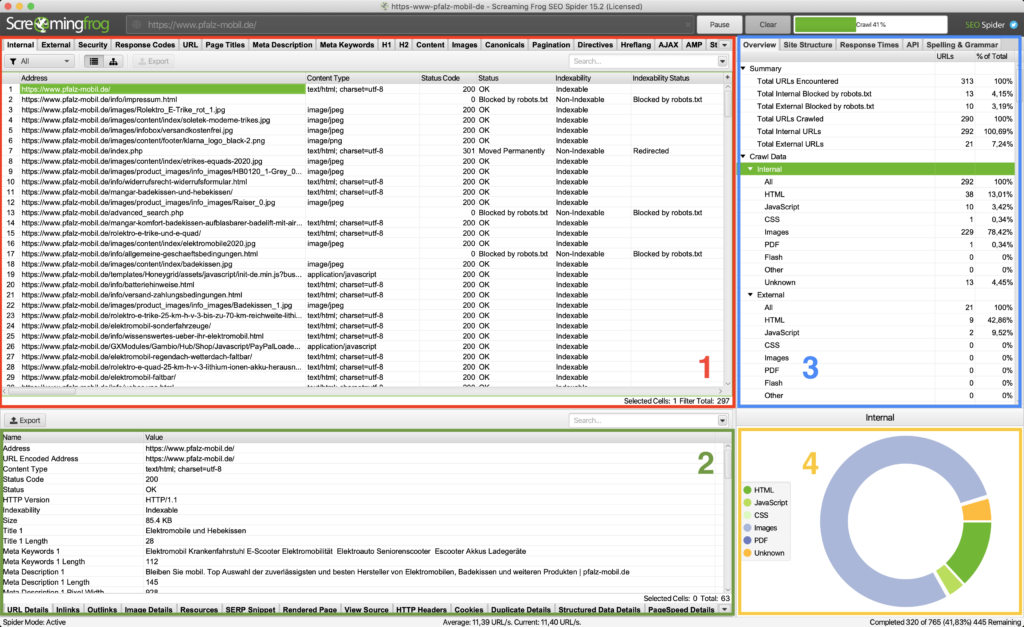
- Bereich 1 (rot): Gesamtübersicht der gecrawlten URLs mit allen verfügbaren Daten. Hier können über die Reiter oben einzelne Daten (z.B. Meta-Daten, Canonicals etc. ausgewählt werden.
- Bereich 2 (grün): Wenn in Bereich 1 eine oder mehrere URLs ausgewählt sind, erscheinen in Bereich 2 die Details. Im ersten Reiter sind die URL Details, die es auch in Bereich 1 gibt, aber untereinander und nicht nebeneinander. Bei Inlinks werden die eingehenden Links auf diese URL gezeigt, bei Outlinks die von dieser URL ausgehenden Links. Das sind die wichtigsten Reiter für reguläre Seiten.
- Bereich 3 (blau): Filter! Super praktisch. Hier finden sich die Übersicht und Auswertung der URL-Details, bspw. Angaben zu überlangen Meta-Daten, Länge und Anzahl von H1-Überschriften, URL-Aufbau etc. Ein Klick auf ein Detail öffnet in Bereich 1 die entsprechende Auflistung der betroffenen URLs. Mithilfe dieses Bereichs könnt ihr die Monsterliste in Bereich 1 also genau nach dem filtern, was ihr braucht.
- Bereich 4 (gelb): Eine grafische Aufbereitung der gecrawlten URL-Typen. Hier kann abgelesen werden, wie hoch der Anteil von Bildern, CSS-/JS-Dateien, PDFs und normalen HTML-Seiten ist. Kann interessant sein, um z.B. sehr bildlastige Seiten zu identifizieren oder um aufzuzeigen, dass zu viele CSS-/JS-Dateien geladen werden müssen. Ansonsten eher unwichtig.
Aufgabe für die Nesthäkchen
Pro Tipp: Lies dir alle Punkte zuerst durch. Die Standard-Einstellung unterscheidet sich bei einem Punkt (ist aber nicht explizit angegeben ;)).
Ich möchte mir für die Kundenwebsite pfalz-mobil.de Folgendes anschauen:
- Crawle nur HTML-Seiten ohne Parameter (Query Strings) sowie ohne CSS-, JS- und SWF-Dateien.
- Crawle als Google-Bot für Smartphone.
- Gibt es 404-Fehler? Falls ja, wie viele und von wo werden diese fehlerhaften URLs verlinkt?
- Gibt es Meta-Titles, die mehr als 561px haben und falls ja, welche Seiten sind das?
- Gibt es Meta-Descriptions, die mehr als 990px haben und falls ja, welche Seiten sind das?
- Wie viele URLs beinhalten Sonderzeichen (Non ASCII Characters)? Exportiere eine Liste dieser URLs!
- Wie viele interne Links aus dem Content hat die URL https://www.pfalz-mobil.de/mangar-badekissen-und-hebekissen/ und welche Linkanker haben diese?